Symas Corp., September 2018
First we'll continue using the 300GB databases as we operated on them before, with only 64GB of system RAM available. Then we'll increase system RAM to 128GB and retest, and then again with system RAM increased to the full 192GB installed in the machine. All of these tests are using ext4 filesystem with journaling disabled. As before, the test uses a single writer with an increasing number of readers, up to the maximum number of hardware threads in the system. The number of reader threads is set to 1, 2, 4, 8, 16, 32, and 63 threads for each successive run. All of the threads operate on randomly selected records in the database. Additional details of the test setup are available on the previous page. Thanks again to Packet and Intel for providing the test system and all their assistance.
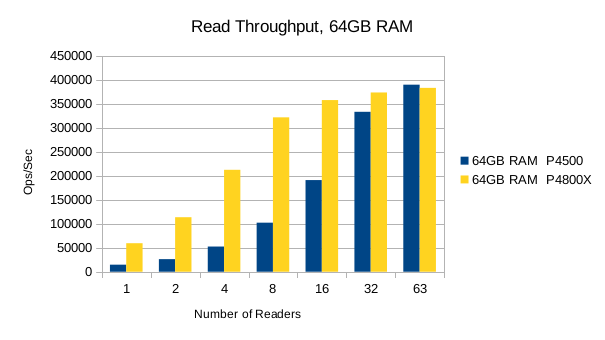
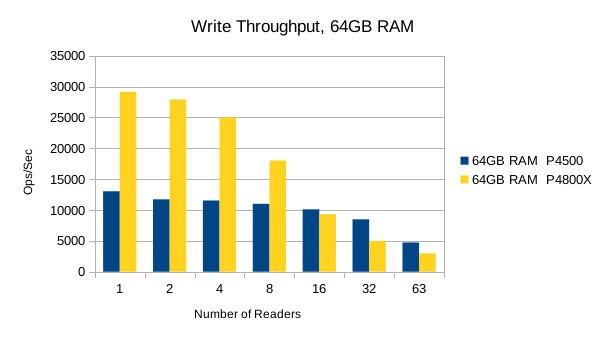
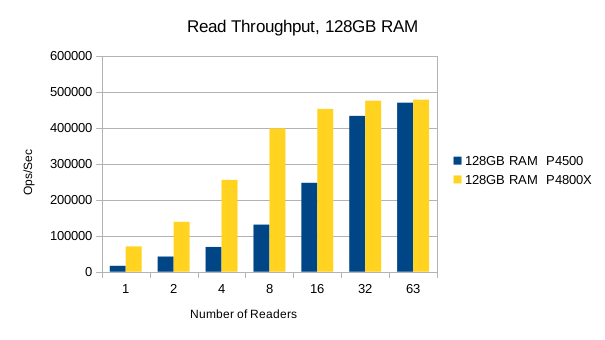
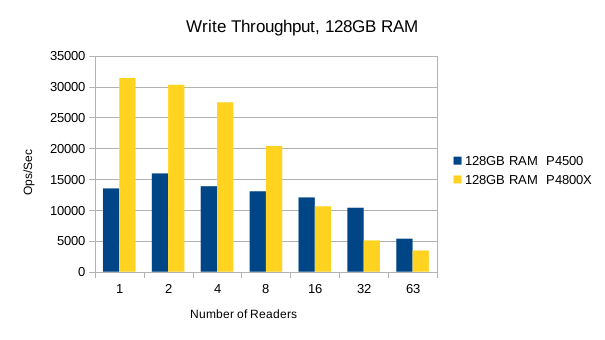
The Optane SSD is generally faster than the Flash SSD. Above 8 reader threads, the readers' bandwidth utilization starts to choke out writers on the Optane SSD, and its write performance drops below the Flash SSD's. The implication here is that the Optane SSDs favor reads at heavier load levels.
It's worth pointing out that up to the 8 readers/1 writer load level, the Optane SSD is ~3.5x faster than the Flash SSD for reads, and ~2x faster for writes. For mixed workloads up to 90/10 read/write, the Optane SSD is definitely worth looking into. For systems that experience high random write rates, the Optane SSD is clearly better than Flash. A throughput advantage of this magnitude means LMDB users can literally hit their SLA with 1/2 as much RAM as otherwise.
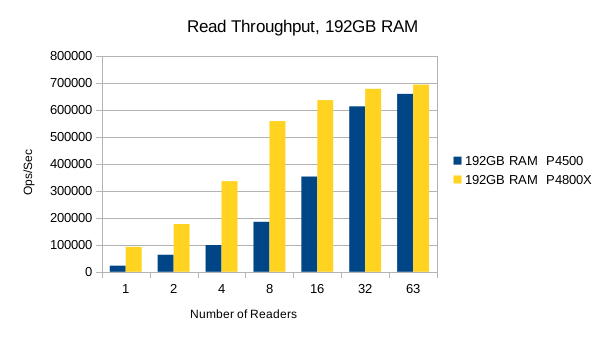
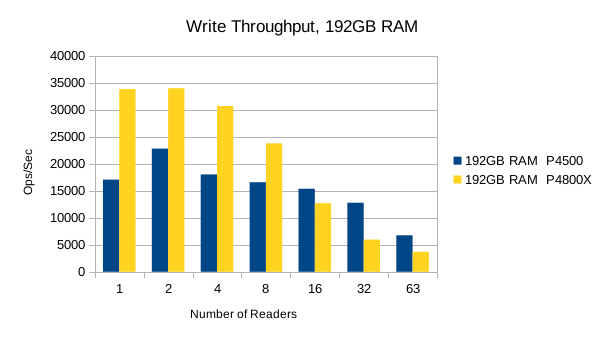
Or in summary
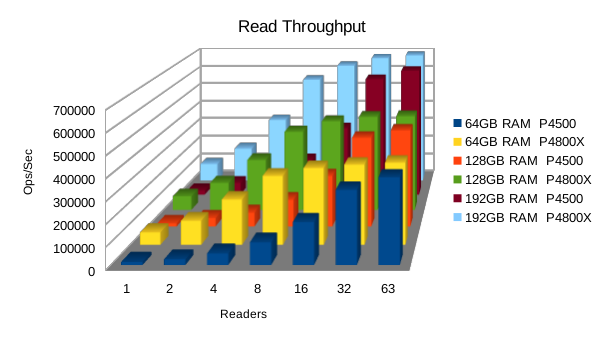
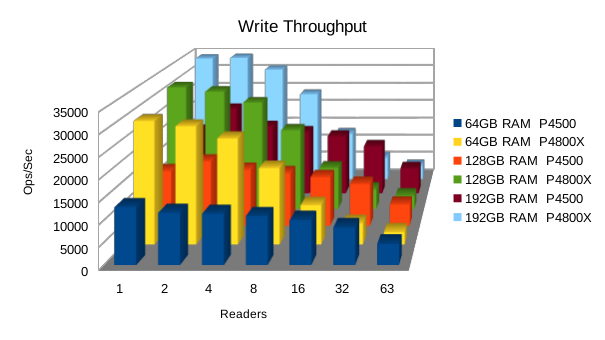
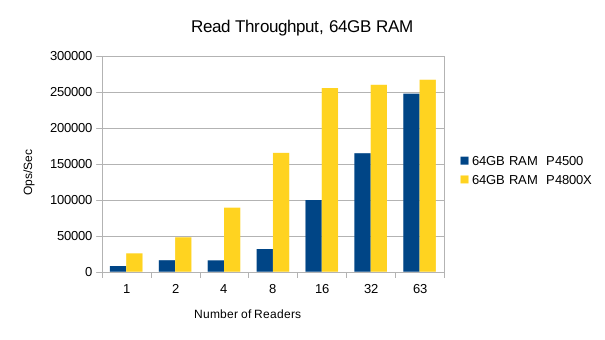
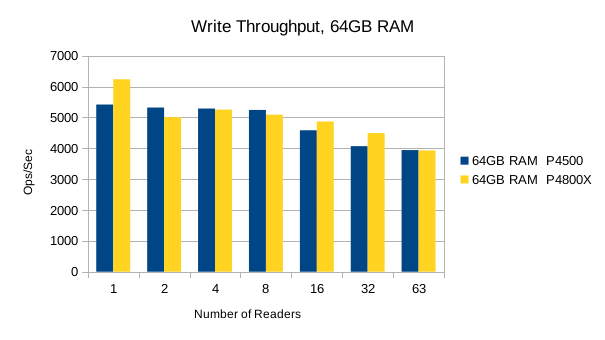
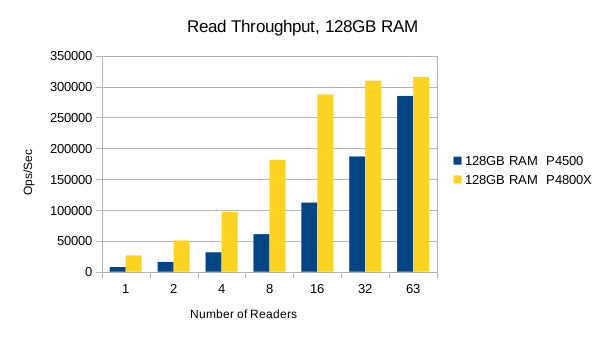
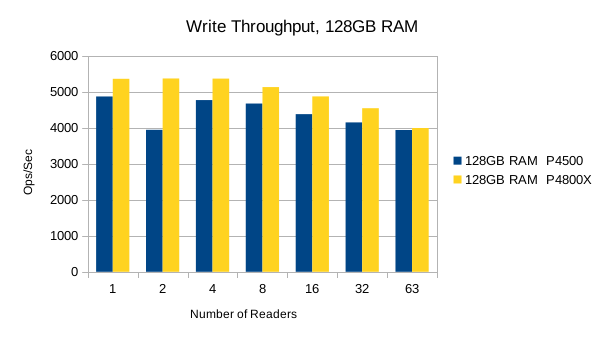
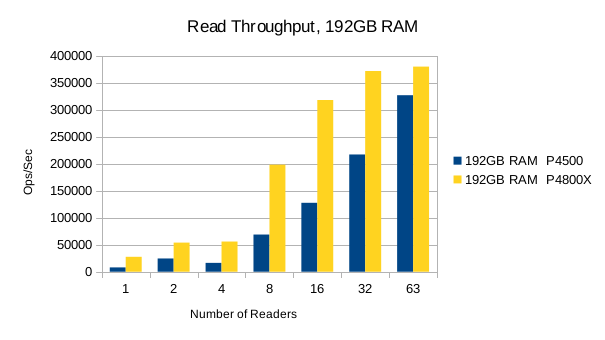
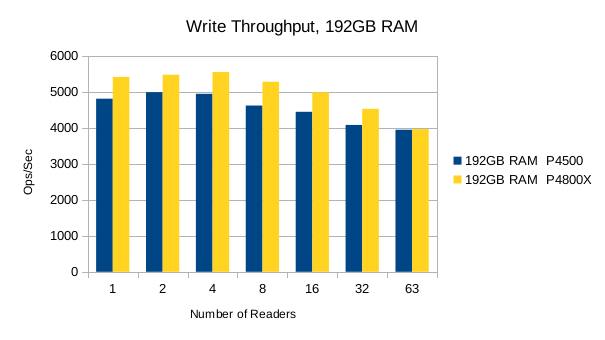
Or in summary
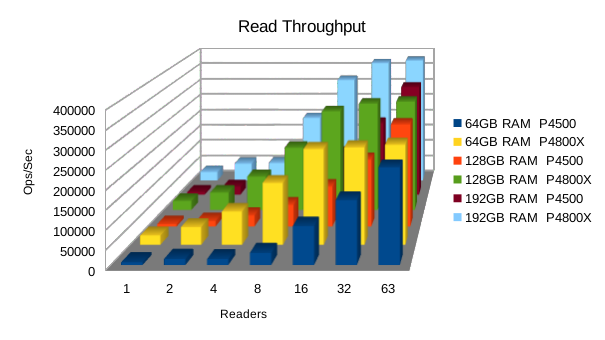
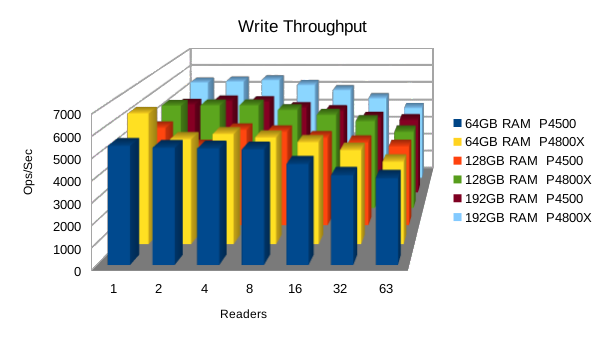
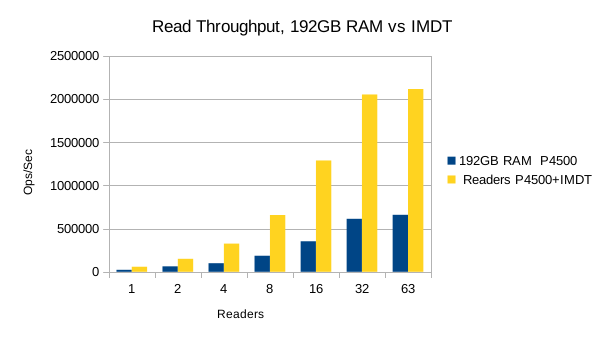
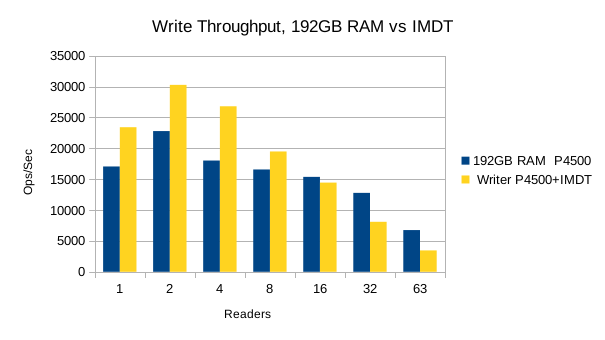
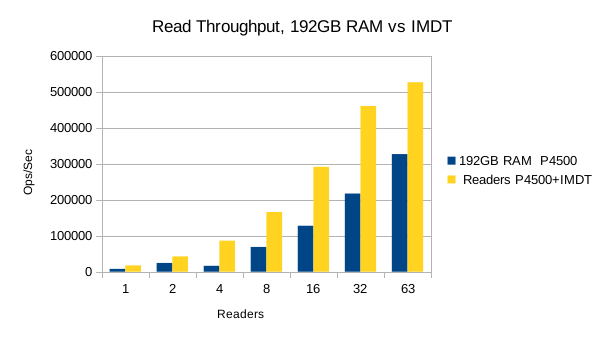
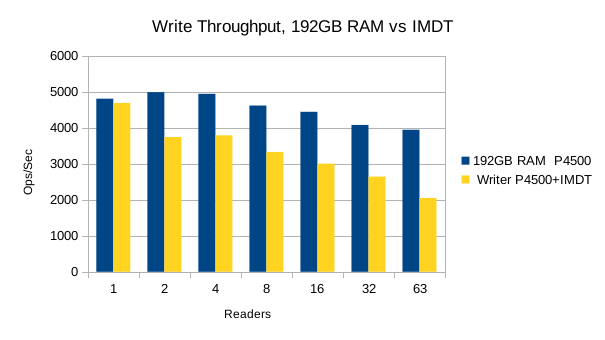
Also, we had to abandon testing of RocksDB for these tests because it was so slow and taking too long to load each new DB. Only results for LMDB are presented below.
| DB | Load Time | CPU | DB Size | Context Switches | FS Ops | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Wall | User | Sys | % | KB | Vol | Invol | In | Out | Write Amp | |
| 400GB | 24:18.73 | 03:45.88 | 19:18.94 | 94 | 403354944 | 13799 | 1538 | 16 | 806726520 | 8.0672652 |
| 800GB | 40:53.68 | 06:02.74 | 34:37.74 | 99 | 806709744 | 255 | 2137 | 968 | 1613419544 | 8.06709772 |
| 1200GB | 01:06:24.00 | 09:33.75 | 56:38.41 | 98 | 1210064592 | 2579 | 8744 | 0 | 2420133840 | 8.0671128 |
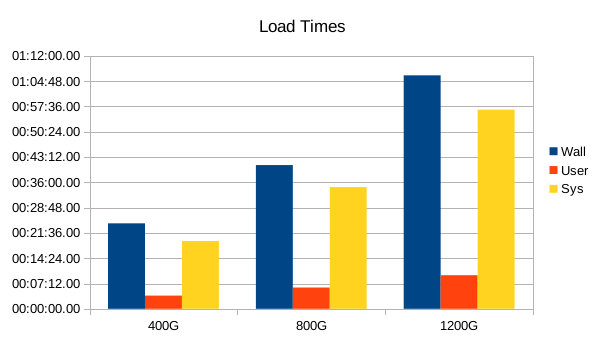
The load speed is essentially linear. It's also interesting to note that the FS Inputs column is effectively zero for each of these loads, which means no metadata was ever forced out of cache and needed to be reread. I.e., the loads are behaving as expected for a fully in-memory DB. Also, the write amplification factor is essentially constant, which is typical for LMDB. (It's really logN with a very large base, so it grows very slowly as DB sizes increase.) The 25% overhead we saw previously, from filesystem metadata overhead, is absent here. Again, this is in line with a fully in-memory workload; everything fit into memory so there were no extraneous metadata flushes from the ext4 fs driver. However, compared to the 13:21.04 it took to load a 300GB DB without IMDT, there's clearly some heavy overhead for IMDT to support writes here.
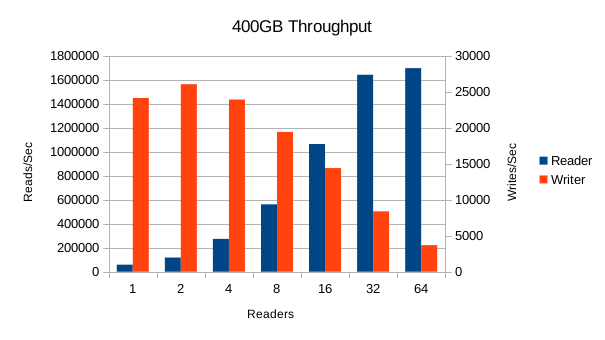
Performance for the 400GB DB looks good. Read throughput peaks at almost 1.7M reads/sec.
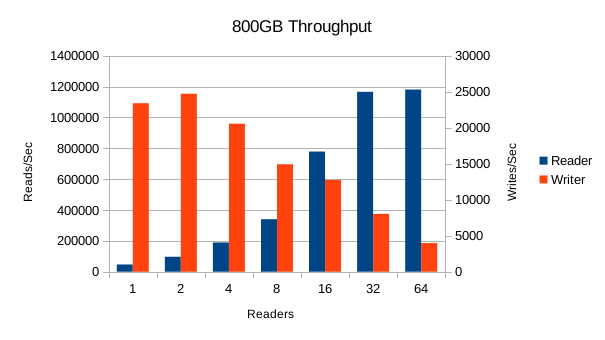
Performance with 800GB is slightly slower, but still good. Read throughput peaks at almost 1.2M reads/sec.
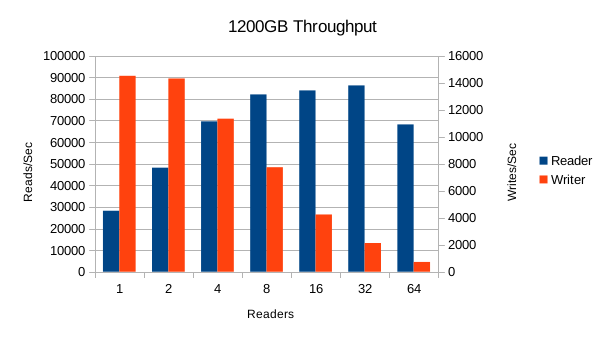
Performance with 1200GB is significantly slower. The numbers are what we'd
expect for a typically larger-than-RAM execution, peaking at only 86K reads/sec.
The results are so far out of line from the previous two tests that we're not
very confident in the reliability of this result. We encourage you to rerun
and verify these results for yourself.
Conclusion
Using the IMDT with Optane SSDs can significantly boost performance with larger DBs, making
a system with limited RAM perform as if it had much more physical RAM. There are limits though,
and it appears that exceeding about a 4:1 ratio of Optane:RAM will nullify the performance
benefits. (Note that this 4:1 ratio is based on uncertain results from the 1200GB test, so
take it with a grain of salt. Your mileage will certainly vary as far as the ratio of Optane:RAM. The
Setup Guide shows that configs up to 8:1 are supported.)
255306652 Aug 27 04:01 imdt1.tgz Command scripts, output, atop records
411606600 Sep 23 20:01 imdt2.tgz Command scripts, output, atop records
LibreOffice spreadsheet with tabulated results here.
The source code for the benchmark drivers
is all on GitHub.
We invite you to run these tests yourself and report your results back to us.