Symas Corp., February 2015
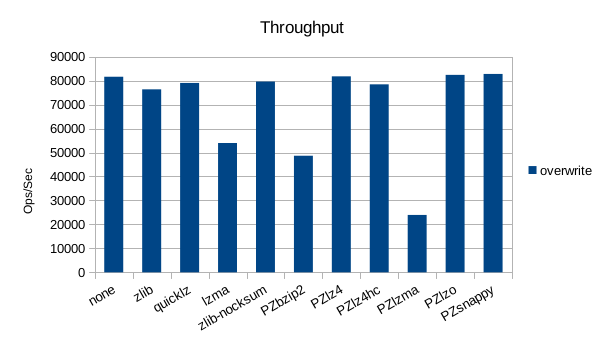
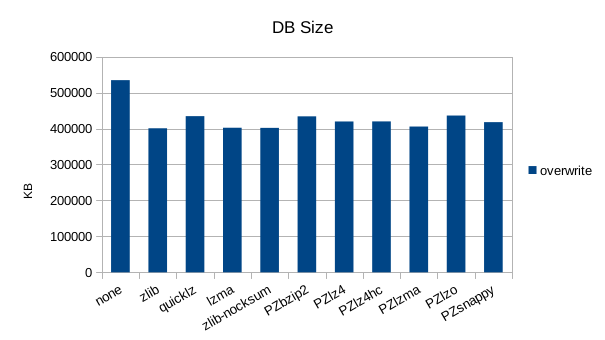
These charts show the final stats at the end of the run, after all compactions
completed. The RSS shows the maximum size of the process for a given run. The
times are the total User and System CPU time, and the total Wall Clock time to
run all of the test operations for a given compressor.
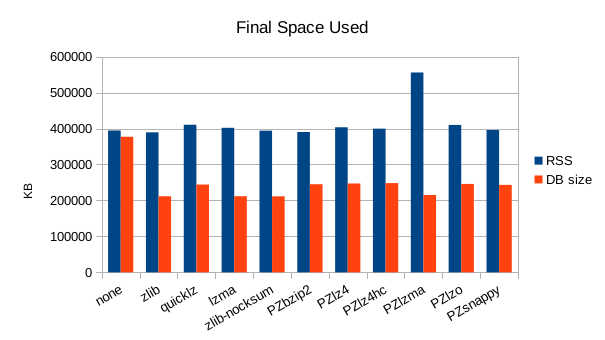
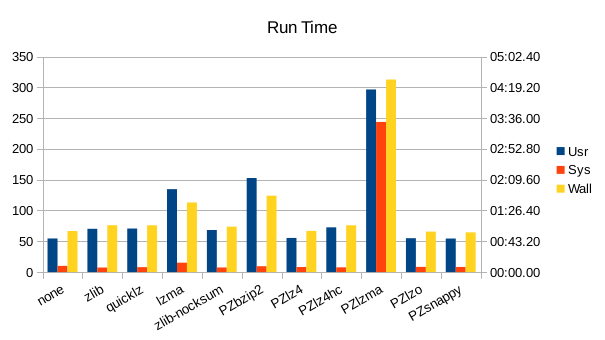
Apparently the settings we chose for our LZMA invocation are too resource-intensive,
it uses a lot of CPU and memory for not very great space savings. The native LZMA
support in TokuDB is much more frugal while still delivering about the same degree
of compression.
The command script: cmd-toku.sh. Raw output: out.toku.txt. OpenOffice spreadsheet TokuDB.ods.