
Compressor Microbenchmark: RocksDB
Symas Corp., February 2015
Test Results
Synchronous Random Write
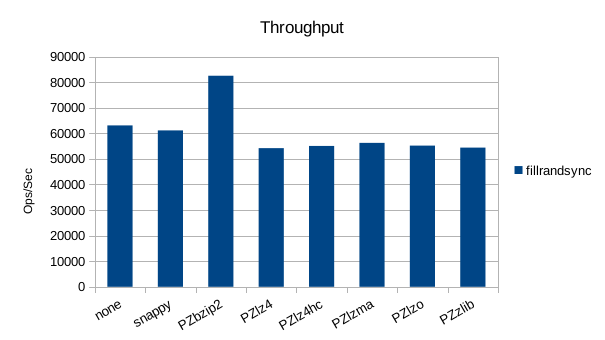
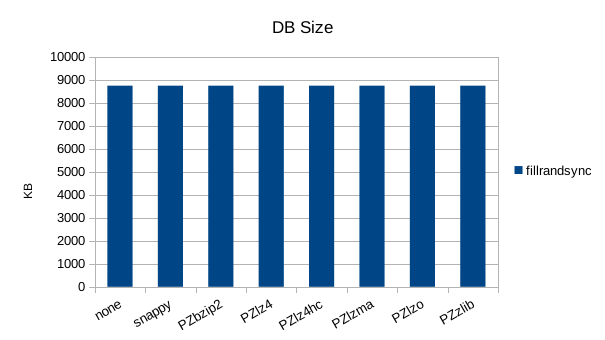
The synchronous tests only use 1000 records so there's not much to see here. 1000
records with 100 byte values and 16 byte keys should only occupy 110KB but the size
is consistently almost 9MB here, showing a fixed amount of incompressible overhead
in the DB engine. While most of the compressors behave as expected and slow
down the overall throughput, bzip2 is faster than no compression here.
Note that RocksDB has built-in support for bzip2, lz4, lz4hc, and zlib, but that support
was not compiled into our build, so only the PolyZ support is tested here.
Random Write
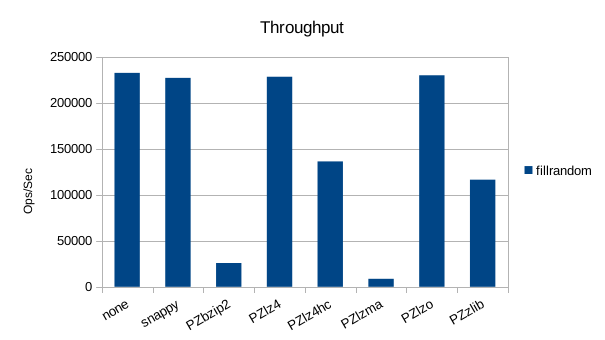
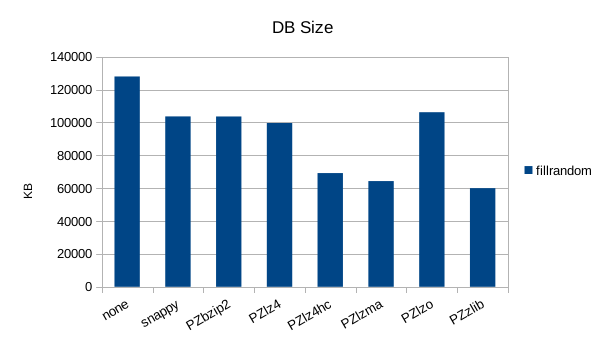
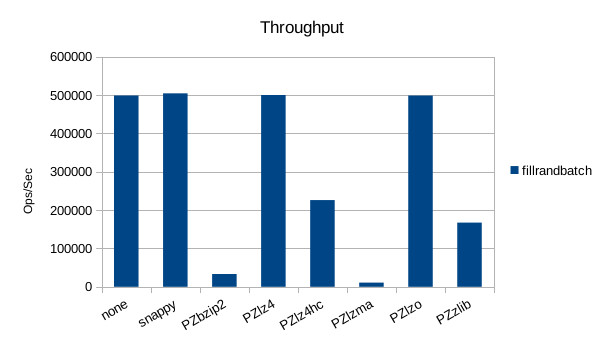
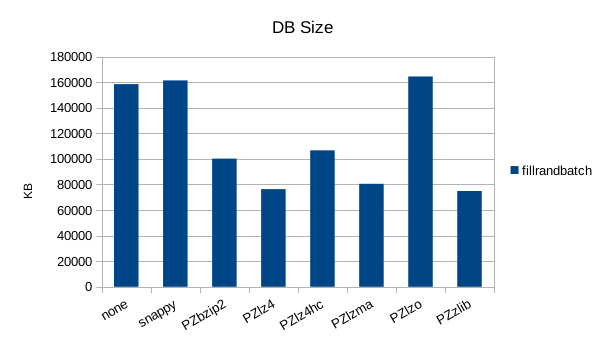
The asynchronous tests use 1000000 records and show drastic differences in
throughput, and notable differences in compression. The general trend for
all the remaining tests will be that snappy, lz4, and lzo are better for
speed, while zlib is better for size.
Random Batched Write
Synchronous Sequential Write
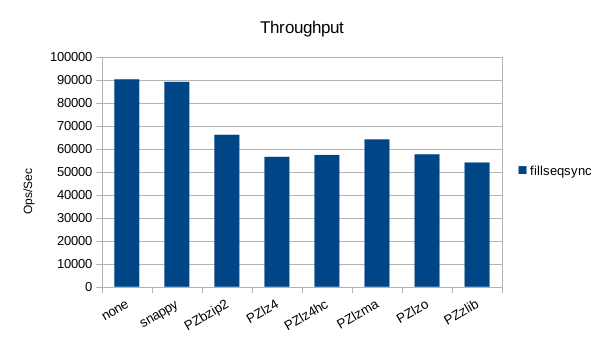
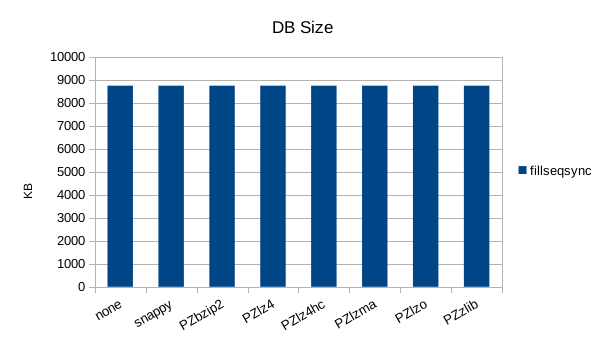
The synchronous tests only use 1000 records so there's not much to see here.
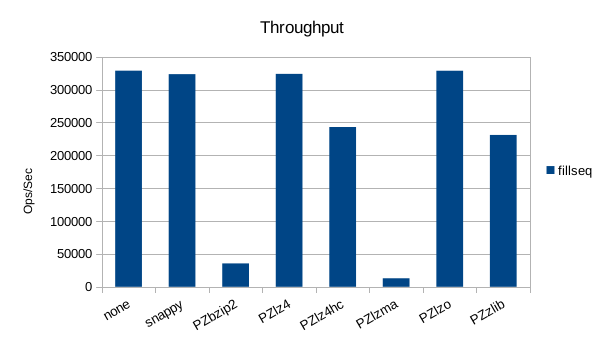
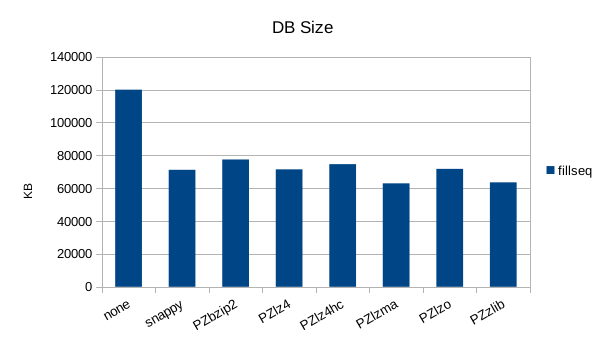
Sequential Write
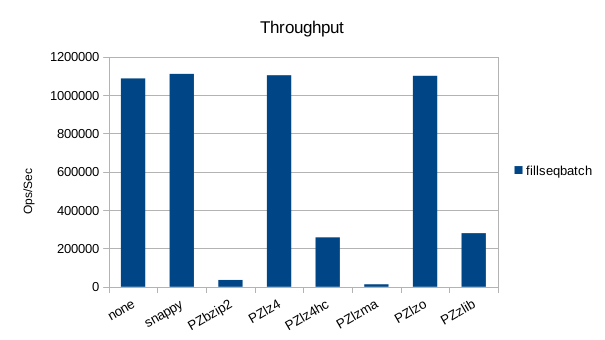
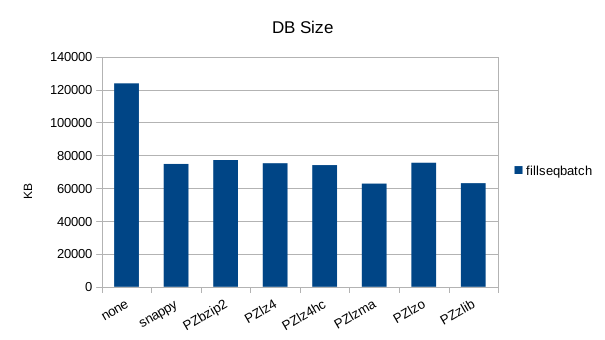
Sequential Batched Write
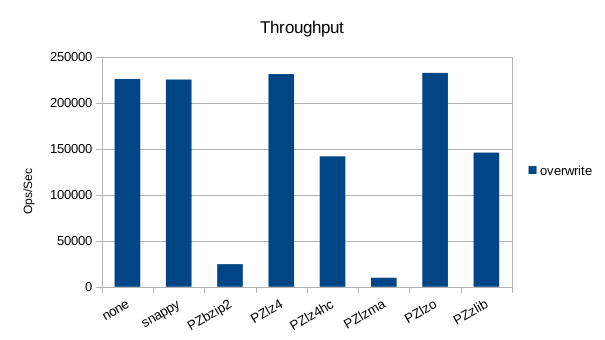
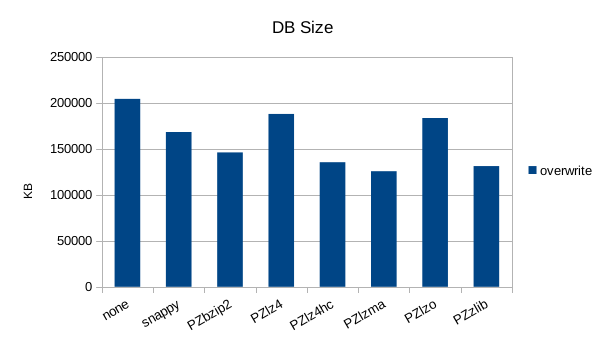
Random Overwrite
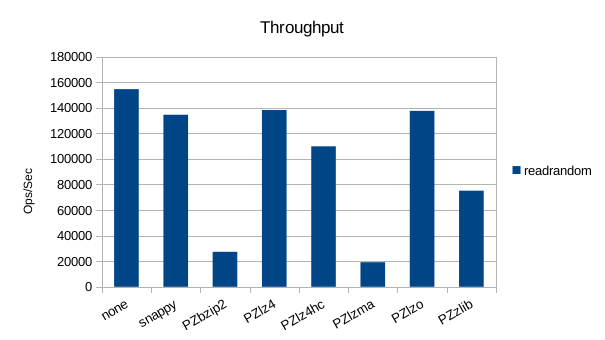
Read-Only Throughput
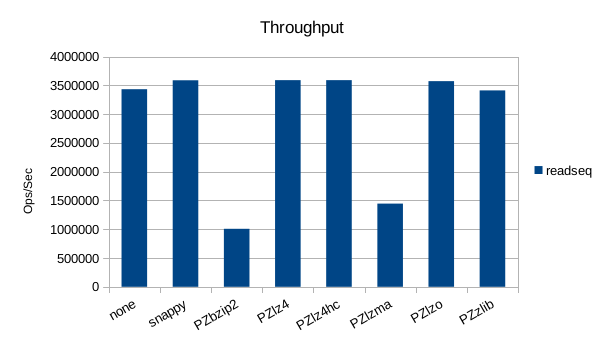
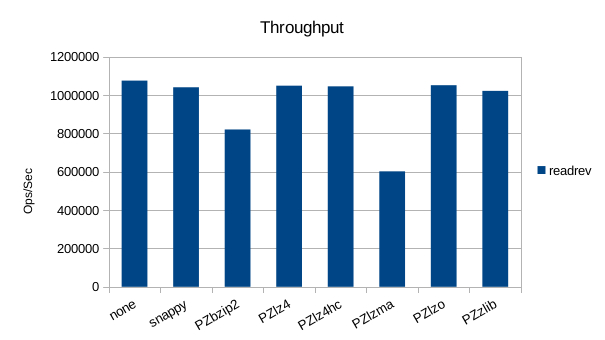
Another surprise here, as snappy, lz4, lz4hc and lzo all turn in throughputs
higher than the no-compression case for sequential reads.
Summary
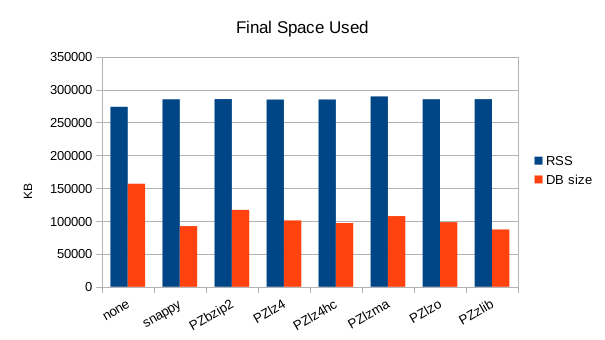
These charts show the final stats at the end of the run, after all compactions
completed. The RSS shows the maximum size of the process for a given run. The
times are the total User and System CPU time, and the total Wall Clock time to
run all of the test operations for a given compressor.
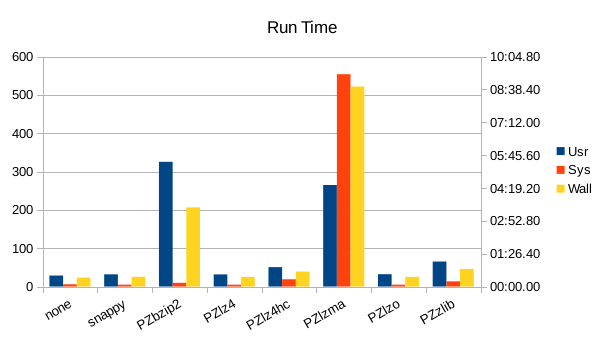
The huge amount of system CPU time in the lzma run indicates a lot of malloc
overhead in that library. zlib still gives the best compression, while
snappy, lz4, and lzo tie for lowest compute cost.
Files
The files used to perform these tests are all available for download.
The command script: cmd-rocks.sh.
Raw output: out.rocks.txt.
OpenOffice spreadsheet RocksDB.ods.