
Compressor Microbenchmark: LMDB
Symas Corp., February 2015
Test Results
LMDB doesn't have any built in compression support at all. The benchmark
program was modified to naively compress every value before storing and
then decompress every value when reading. This generally works OK for a
reader that will never read the same record more than once, but in a
real-world app with multiple reader threads occasionally hitting the same
records, some caching might be useful.
Other DB engines with built-in compression support may have much better
write efficiency, since they will generally compress entire blocks at a
time instead of single values at a time. The downside is that their read
speeds will be slower because an entire block must be decompressed just
to access a single record. Decompression of the rest of the block may
or may not be wasted work, depending on if the application needs to read
the neighboring records.
Synchronous Random Write
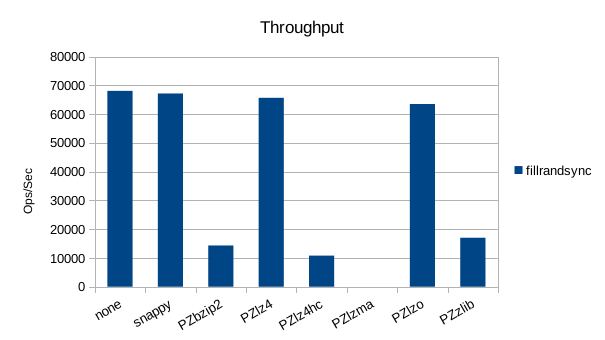
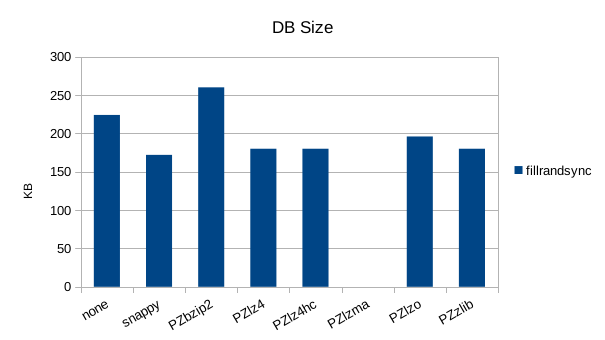
The synchronous tests only use 1000 records so there's not much to see here.
bzip2 does very poorly here, yielding data sizes larger than the original
uncompressed data. lzma did extremely poorly on compression speed, running
at a constant 426 records/second. It was dropped from the tests as each
run of 1000000 records was taking over 45 minutes.
Random Write
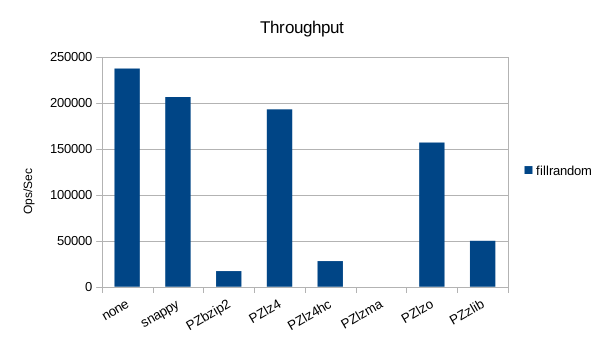
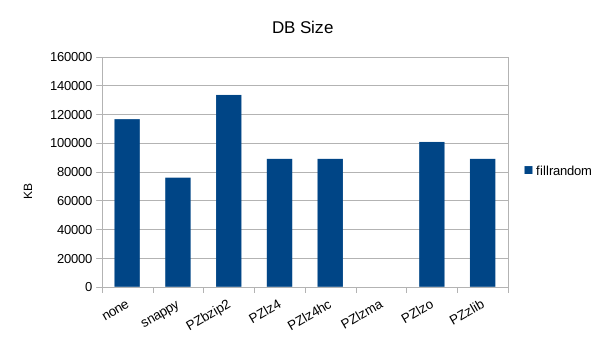
The asynchronous tests use 1000000 records. Snappy seems to be fastest
and smallest in all of these tests.
Random Batched Write
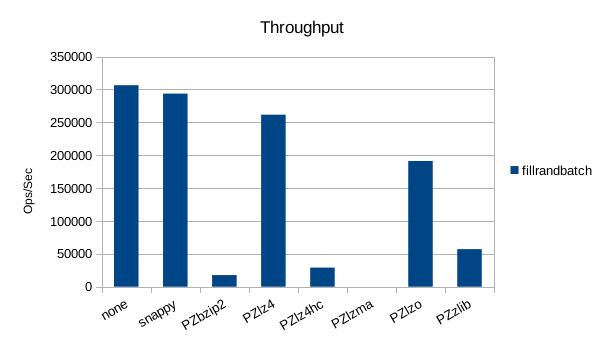
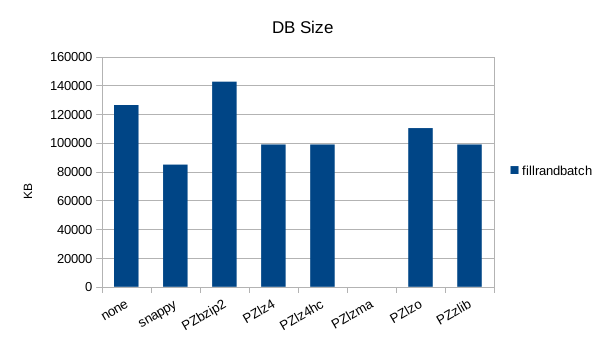
Synchronous Sequential Write
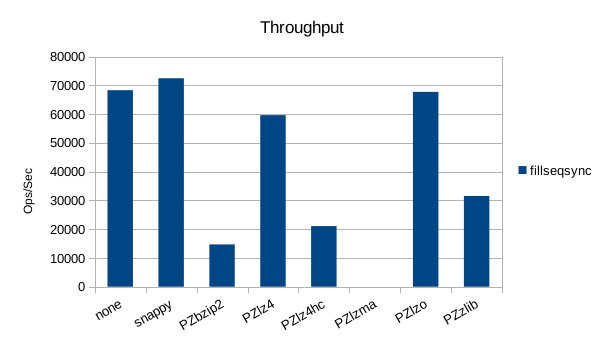
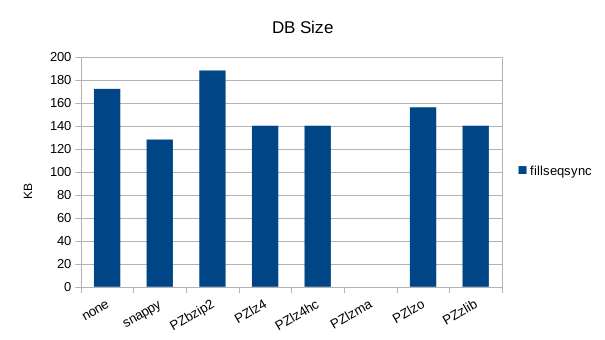
The synchronous tests only use 1000 records so there's not much to see here.
Here snappy is even faster than the uncompressed write, which is surprising.
Sequential Write
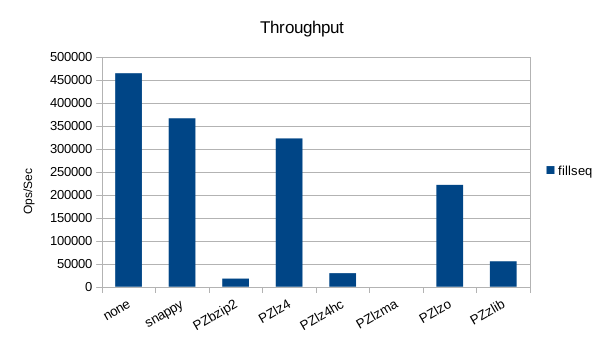
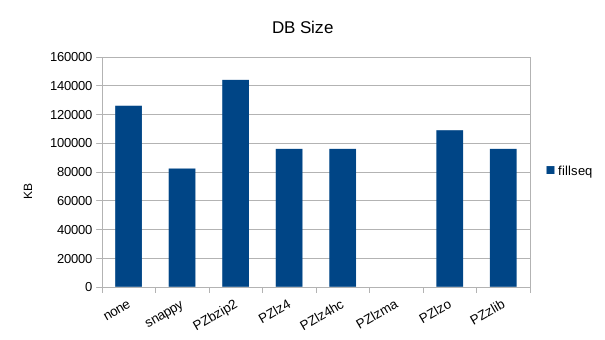
Sequential Batched Write
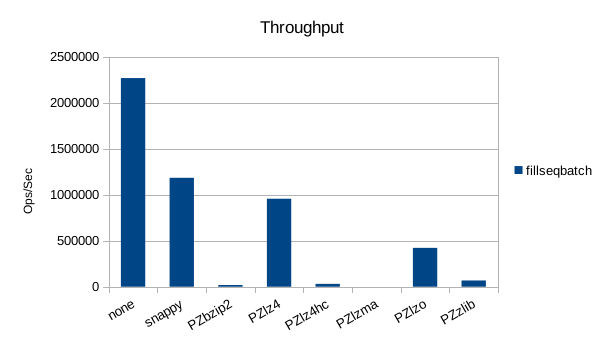
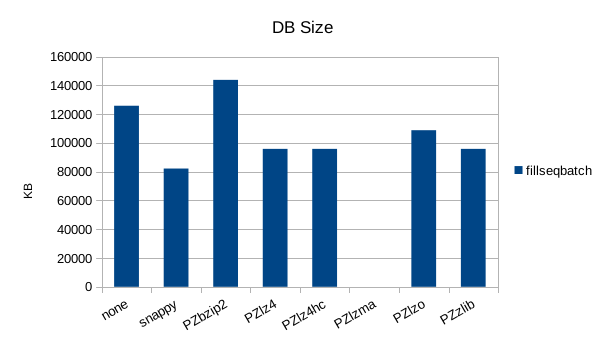
Random Overwrite
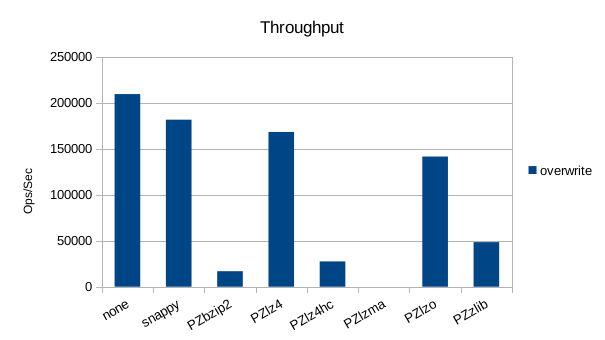
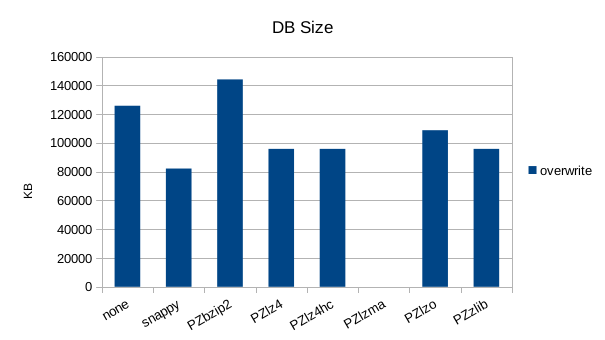
Read-Only Throughput
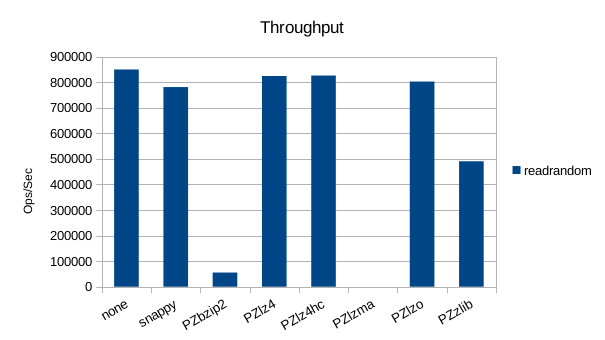
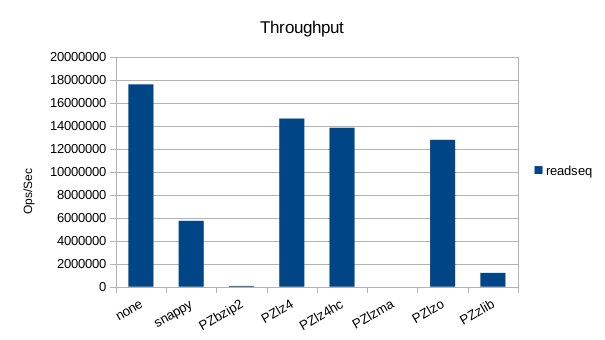
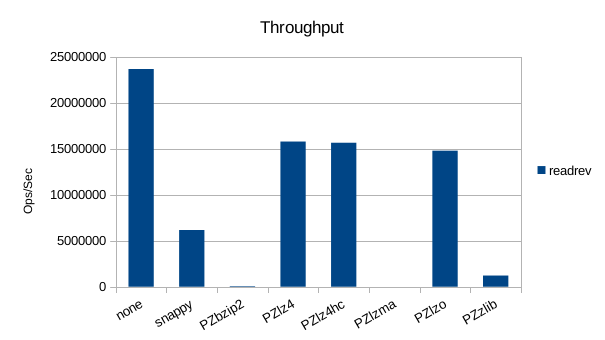
Since LMDB reads are zero-copy and zero-malloc, inserting anything else in
the code path will necessarily be slower. lz4 seems to be the least bad in
terms of performance here.
Summary
These charts show the final stats at the end of the run, after all compactions
completed. The RSS shows the maximum size of the process for a given run. The
times are the total User and System CPU time, and the total Wall Clock time to
run all of the test operations for a given compressor.
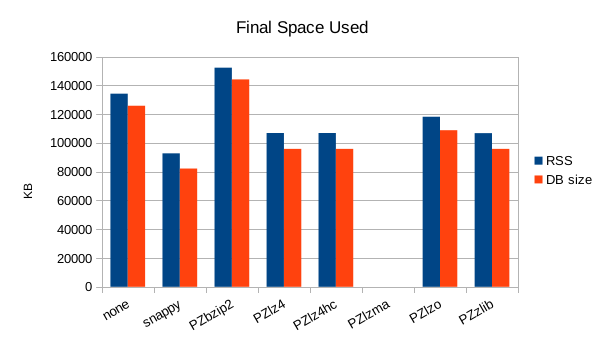
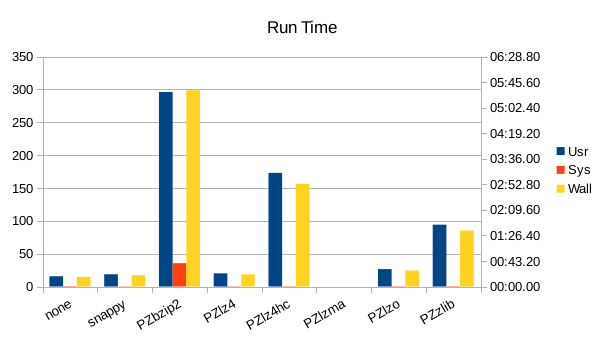
Unlike for other DB engines where zlib usually gave the best compression,
snappy saves the most space here. snappy or lz4 tie for overall speed,
with snappy winning on write speed and lz4 winning on read speed.
The size chart is interesting because the process size is basically a
fixed increment over the DB size. Since LMDB is memory-mapped, it's
normal for the process size to be directly related to the DB size.
What's unusual is that the difference between the process size and DB size
doesn't appear to change for any of the compressors - i.e., whatever
amount of RAM they needed for compression or decompression was constant
across all the compressors. Given the great differences in their
algorithms and code, one would have expected more variation in
memory usage here.
Files
The files used to perform these tests are all available for download.
The command script: cmd-lmdb.sh.
Raw output: out.lmdb.txt.
OpenOffice spreadsheet LMDB.ods.