
Compressor Microbenchmark: HyperLevelDB
Symas Corp., February 2015
Test Results
Synchronous Random Write
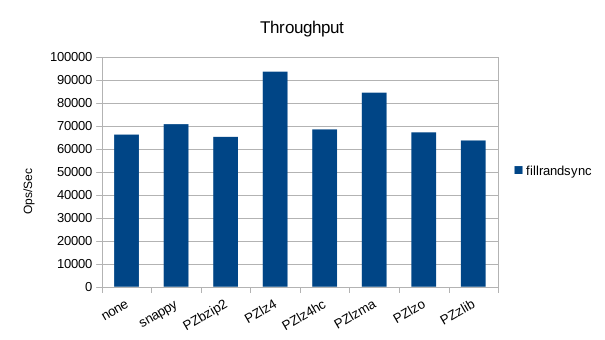
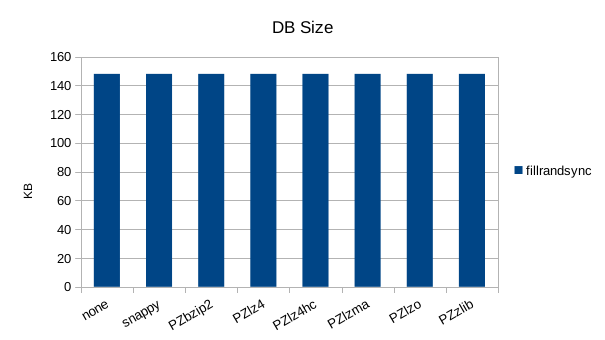
The synchronous tests only use 1000 records so there's not much to see here. 1000
records with 100 byte values and 16 byte keys should only occupy 110KB but the size
is consistently over 140KB here, showing a fixed amount of incompressible overhead
in the DB engine. Surprisingly, several of the compressors turn in faster throughput
than the uncompressed case.
Random Write
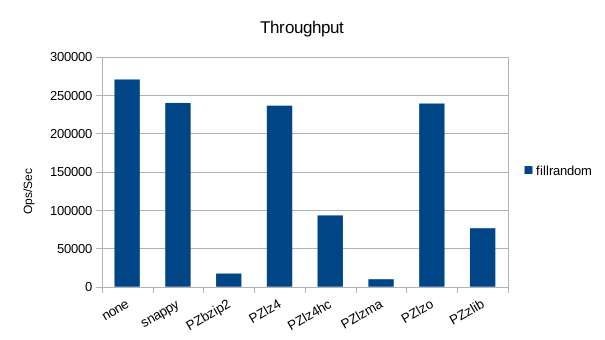
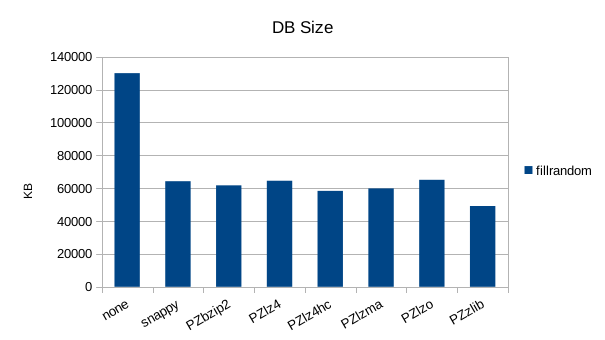
The asynchronous tests use 1000000 records and show snappy, lz4, and lzo to be
the fastest compressors here, while zlib gets the most compression.
Random Batched Write
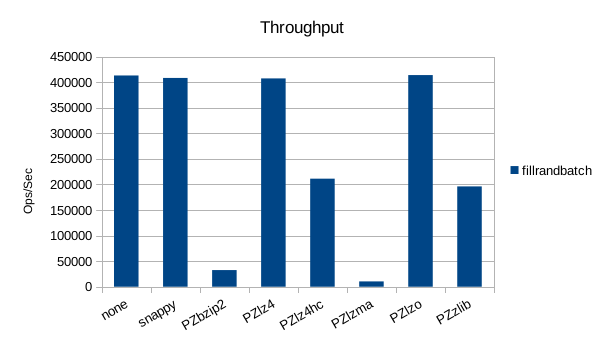
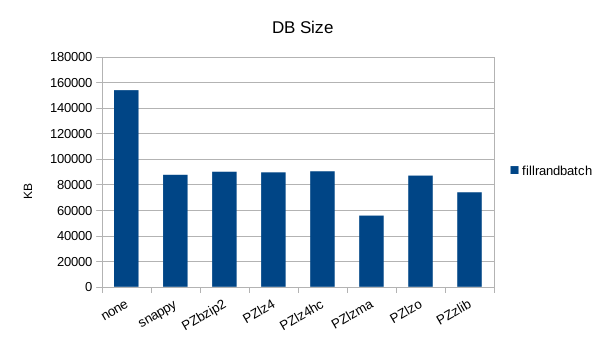
While the throughput matches the results of the non-batched case, with batching
lzma gets the best compression.
Synchronous Sequential Write
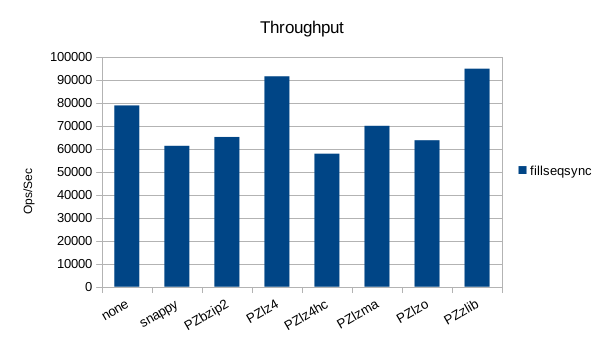
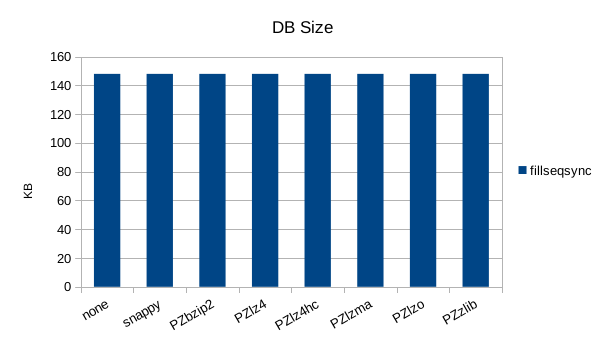
The synchronous tests only use 1000 records so there's not much to see here.
Still, at this small test size, it's surprising to see lz4 and zlib getting
significantly better throughput than the uncompressed case.
Sequential Write
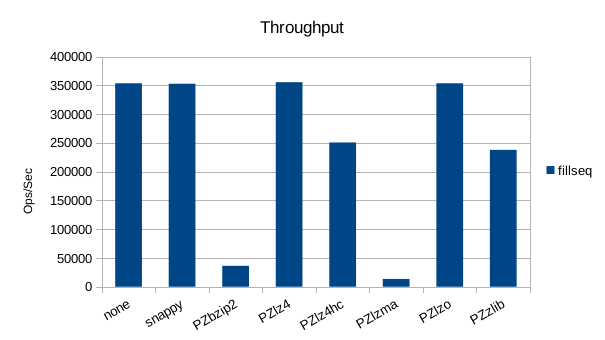
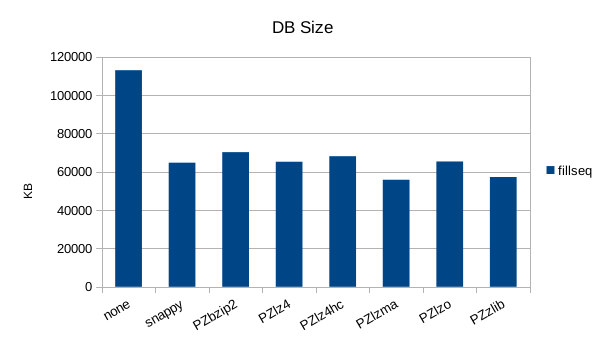
Sequential Batched Write
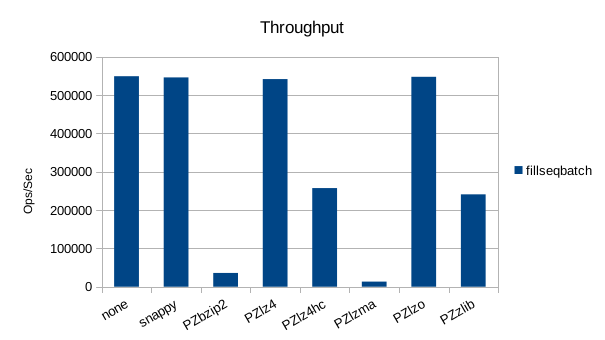
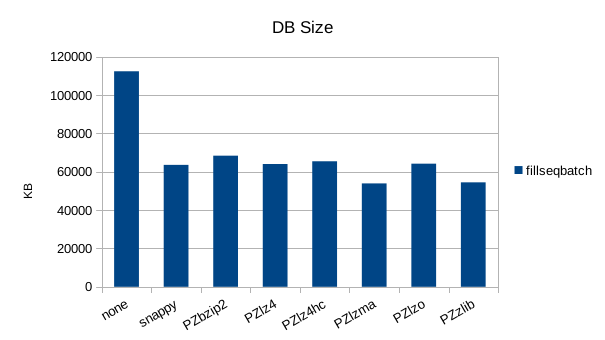
Random Overwrite
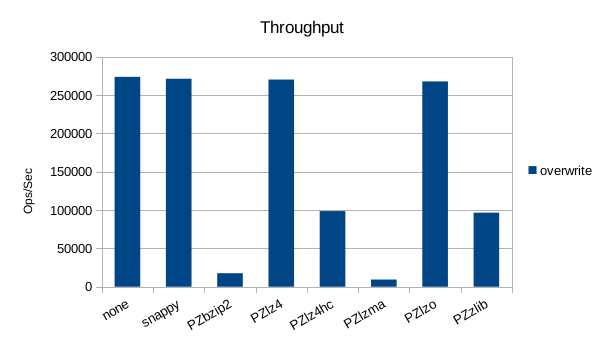
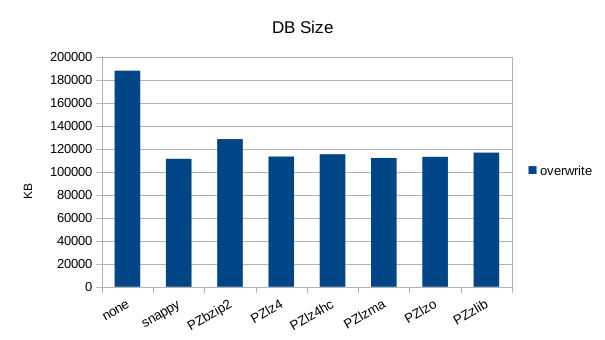
Read-Only Throughput
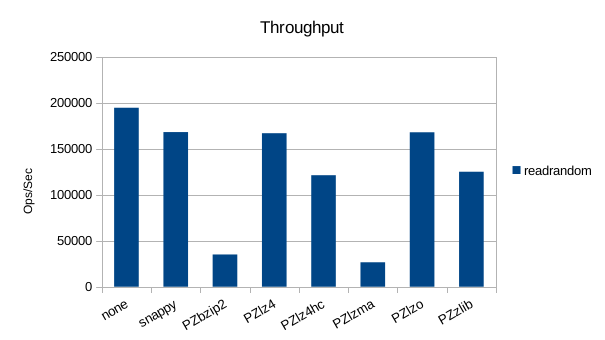
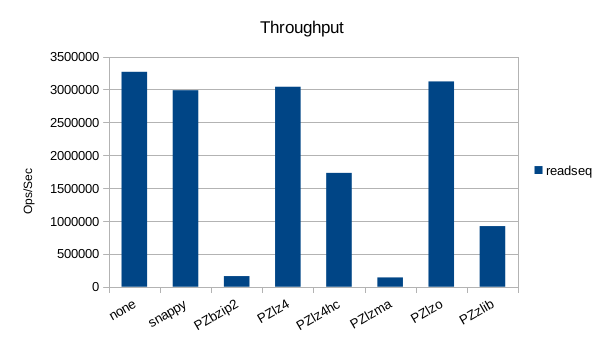
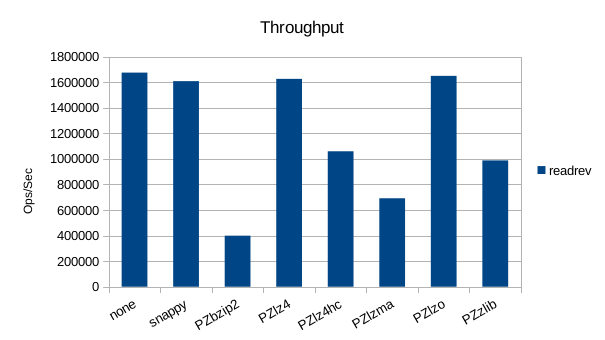
There's a pretty wide range of variation in the throughput here but the
overall rankings of each compressor don't change.
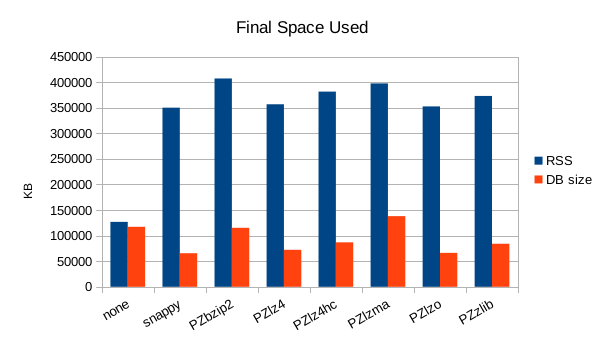
Summary
These charts show the final stats at the end of the run, after all compactions
completed. The RSS shows the maximum size of the process for a given run. The
times are the total User and System CPU time, and the total Wall Clock time to
run all of the test operations for a given compressor.
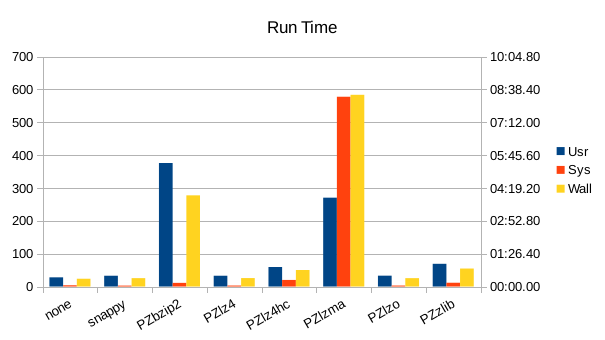
The huge amount of system CPU time in the lzma run indicates a lot of malloc
overhead in that library. The difference is small but overall it appears that
lzo performs best for both compression and speed.
Files
The files used to perform these tests are all available for download.
The command script: cmd-hyper.sh.
Raw output: out.hyper.txt.
OpenOffice spreadsheet Hyper.ods.